This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Looker
- Articles & Information
- Technical Tips & Tricks
- Advanced LookML - Intro Aggregate Awareness
Topic Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content

 LinkedIn
LinkedIn Twitter
Twitter
LookerExperts
Staff
Topic Options
- Article History
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
0
0
1,857
Knowledge Drop
Last tested: Jun 24, 2019
This is a useful method if you have summary tables defined in your ETL process. Otherwise, take a look at our Aggregate Awareness documentation to see if our native option works for you!
Aggregate awareness is a BI term that describes the ability to use aggregate (summary) tables in a database. These summary tables contain pre-calculated data, generally rolled up by week, month, quarter, and year along with key metrics. This is particularly useful in datasets where there is a high level of granularity, stored at a transaction level. Furthermore, by leveraging liquid variables, these tables can then be referenced dynamically from a single Looker Explore.
Let’s look at a common example. Suppose you wanted to get a distinct count of users per year from your event table; consider the two queries below:
Query A - Default Looker query:
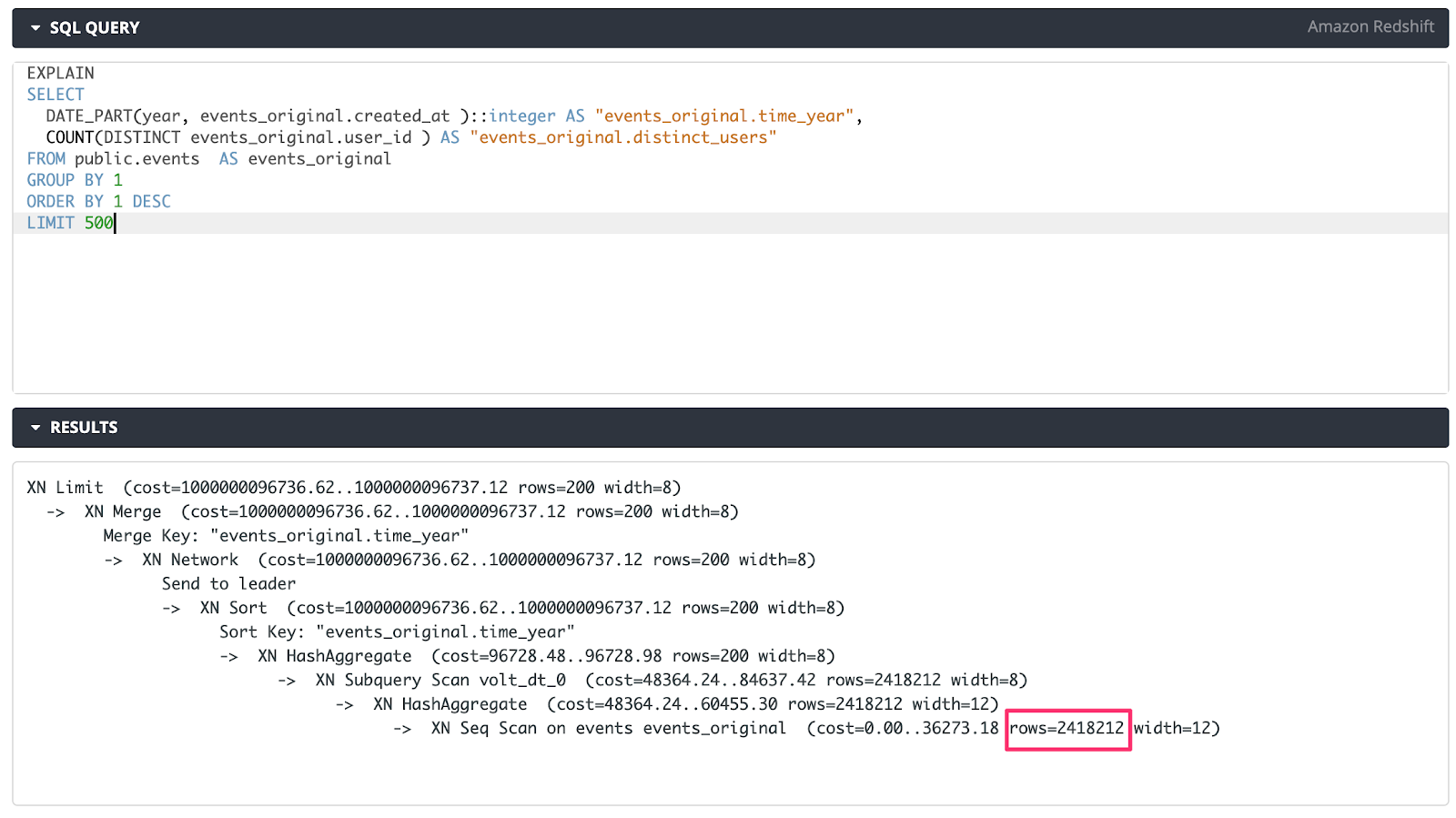
Query B - Leverage a summary table as a CTE:

What we’re actually looking at is the query plan of each query via the EXPLAIN command. This will show information on the individual operations required to execute a query (more information for the Redshift dialect can be found here).
For reference, this will be the results for both queries:
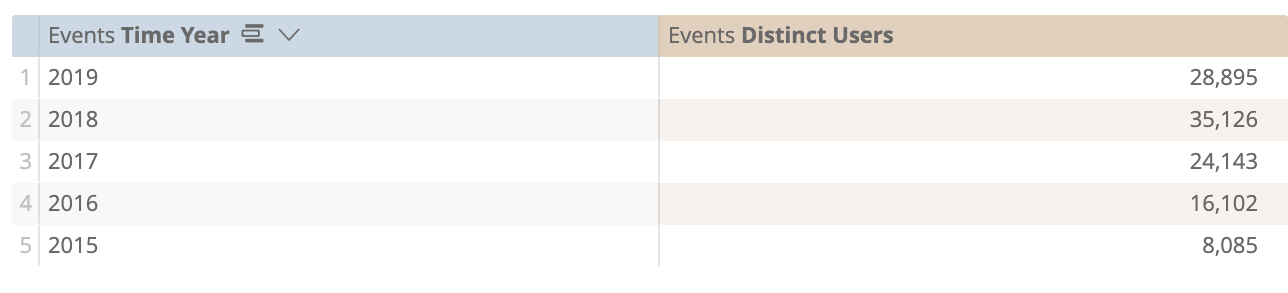
While both queries will have the same result, query B will outperform query A considerably. The reason for this is simply due to the fact that the summary table is already has this information handy and does not need to calculate it at runtime. Query A needs to go down to the event (transactional row) level each and every time it wants to GROUP BY the year timeframe, while the summary table already has this information stored in the table.
Why does this matter?
Now imagine that instead of millions of records, you’re dealing with trillions of records of data, and it’s not a single query, but hundreds of queries that are being run concurrently by end users that follow the same structure. Generally speaking, the query structure looks something along the lines of: “what does X look like by Y timeframe?”
If these queries are run on the row level data, this could consume the database with expensive queries. However, since these queries all follow a similar pattern we can use aggregate awareness to point specific queries to the summary tables.
Leveraging summary tables allows for SQL queries on much fewer rows of data, which results in quicker queries and happy end users. Not only is the individual query faster (as it does not have to select large volumes of granular data), but it will also have a huge impact on all queries on a database connection.
This approach can have a tremendous impact on overall database contention, especially if you have lots of queries against transactional or event level data. This is partly due to the fact that as slow queries run, faster running queries will stack up behind them (much the same way someone driving slow will cause traffic to slow down in general). The more requests that can be satisfied from highly summarized data we can start moving data requests in and out more effectively and reducing the chance of a contention based slowdown.
Fantastic, but how is this dynamic?
Continuing on the earlier example, let’s say you’ve created the following derived tables in Looker:

So now we have 3 summary tables, plus the original table PUBLIC.EVENTS. While this sounds great in theory, it’s going to be difficult to manage multiple Looker Explores and ensure that end users choose the correct one each time. This is where liquid variables comes to the rescue.
The liquid variable view_name.field_name._in_query will return true if the field referenced in the view_name.field_name appears in the query. We can use this within a simple liquid condition to dynamically change the table we are referring to, thus allowing for a single Explore:
derived_table: {
sql:
SELECT Procfile README.md all_cards.json body_after.txt body_before.txt body_during.txt ids.txt jq main.sh tmp FROM
{% if time_date._in_query %}
${event_facts_daily.SQL_TABLE_NAME}
{% elsif time_month._in_query %}
${event_facts_monthly.SQL_TABLE_NAME}
{% elseif time_year._in_query %}
${event_facts_yearly.SQL_TABLE_NAME}
{% else %}
PUBLIC.EVENTS
{% endif %}
;;
}
dimension_group: time {
timeframes: [raw,date,month,year]
type: time
sql: ${TABLE}.TIME ;;
}
So if we build an Events Explore based on the above derived table, we can dynamically change which table we query based on the timeframe:
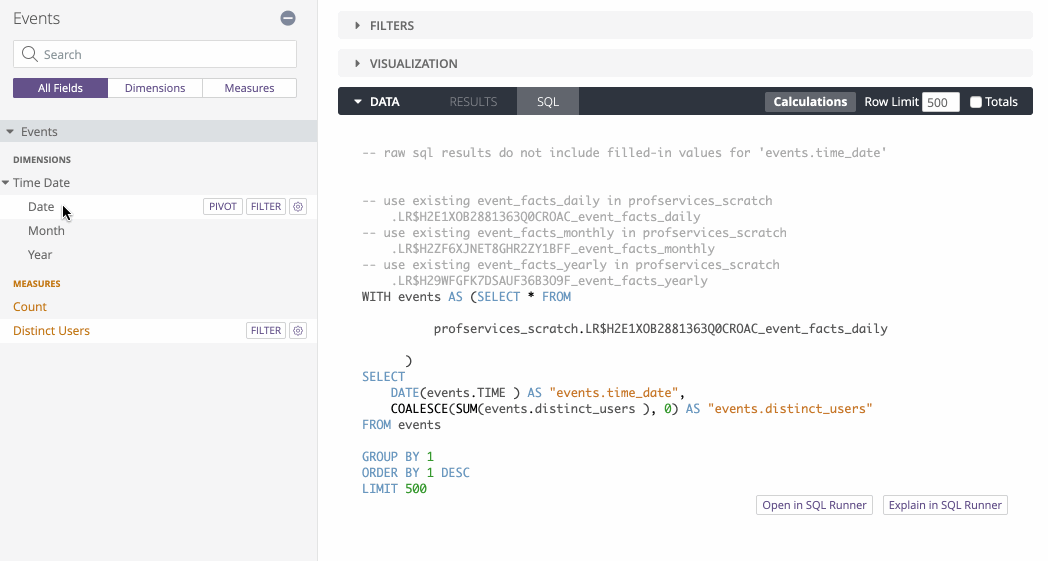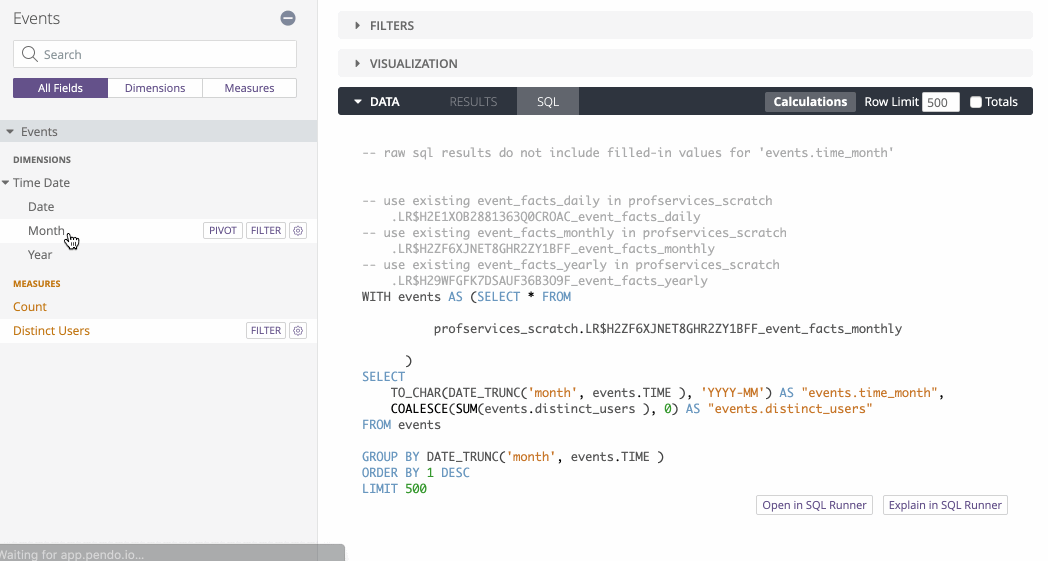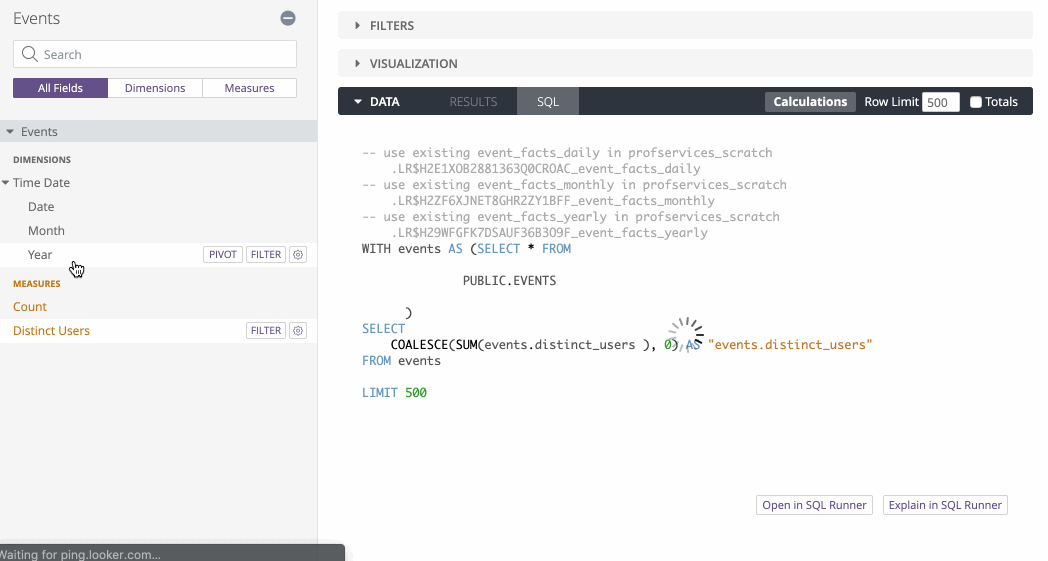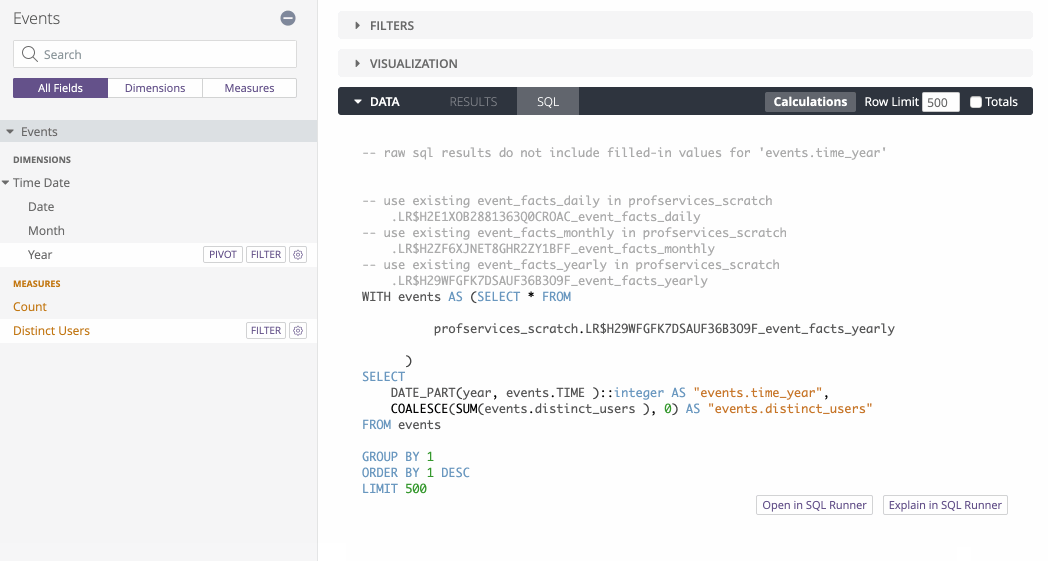
See how the SQL changes depending on which timeframe is selected?
You will also need to pay special attention to the liquid conditions used for the measures to ensure the measure is generating the appropriate SQL based on the dimension you have selected.
measure: count {
type: number
sql:
{% if time_date._in_query or time_month._in_query or time_year._in_query %}
SUM(${TABLE}.count)
{% else %}COUNT(*)
{% endif %}
;;
}
measure: distinct_users {
type: number
sql:
{% if time_date._in_query or time_month._in_query or time_year._in_query %}
SUM(${TABLE}.distinct_users)
{% else %}
COUNT(DISTINCT ${TABLE}.user_id)
{% endif %}
;;
}
Things to Know
The summary tables will need to have identical columns, so that no matter which fields are selected, the query will not error. Because these tables can take a very long time to generate (depending on how much data there is), it is best practice that they be defined in ETL.
This content is subject to limited support.
Topic Labels