This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Looker
- Looker Forums
- Modeling
- BQML blocksを使ってLookerでBQMLしましょう
Topic Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Solved


 LinkedIn
LinkedIn Twitter
TwitterPost Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Reply posted on
--/--/---- --:-- AM
Post Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
※ 本投稿はLooker Advent Caledar 2021 22日目の記事です。
年末にお小遣い稼ぎをしようと、株を買ってみようとしたんですが、せっかくなのでLookerでBQMLを使って予測した結果を元に売り買いしてみようじゃないかというのが動機です。(良い子は絶対マネしないように)
今回は、特定の株価がある時点でいくらになっているかというのを予測します。予測に使う株は伊藤ハムです。筆者は肉を食べないのですが、伊藤ハムから出た大豆ミートのチキンナゲットが本当においしかったので、将来伸びるかなという期待を込めて選定しました。
前置きはこんなところで、どうやってやるかを説明します。
今年、Lookerのマーケットプレイスにて、BQML blocksが登場しました。今回はこちらをカスタマイズして使っていきたいと思います。
このblocksの作りとしては、BQMLのモデルを作るところや、予測等を動かすためのSQL(CREATE MODELやML PRDICT等)はすでにblocksで書かれているので、カスタマイズするのは、あくまでトレーニングデータを作る部分のみになります。
このBlocksのLookMLは独特な作りをしているので、初見だと取っ付きにくい印象ですが、Exploreの画面で、フィールドを順番どおりにクリックしていくだけで、予測ができるようなユーザフレンドリーな仕様になっています。
始める前に前提条件があります。
-
サービスアカウントにBigQuery Data Editor および BigQuery Job User predefined rolesが適用されていること
-
LookerPDTが今回使用するデータベース接続の設定で有効化されていること
- PDTはデータベース接続時に設定したtemp datasetに作成されていきます。その際、元のデータが格納されているデータセットのRegionと、このtemp datasetのRegionは必ず同じである必要があります。
例えば、このblocksにすでにサンプルとして定義されているGA360のパブリックデータですが、このデータはUS Regionに入っているので、このtemp schemaもUSで作成する必要があります
今回は、株価の予測なので、BigQuery ML Time-series Forecasting (ARIMA)モデルを使います。各モデルによって、blocksが分かれるので、用途に応じてインストールしてください。
カスタマイズの仕方
-
Marketplaceからのインストールすると、プロジェクトの中に、
- imported projects
- arima_model_info.model/google_analytics_forecast.model(read-only)
- refinements.lkml
- manifest.lkml
が入っています。初期状態では、GA360のパブリックデータを元に、Forcastができる状態になっています。imported projectsの中をざっくり説明すると、
input_data.viewがトレーニングに使用するデータを抽出する用
それ以外のviewはBQMLのクエリを作るのに使う用(基本的には触りません)
- 今回は、株価予測をしたいので、このユースケース専用のフォルダを作成し、また専用のモデルファイル、explore、input_data.viewを作成していきます。
フォルダ構成 stock_price_forcast.model 中身
connection: "my_stockdata"
include: "*.view.lkml"
include: "//bqml-arima/explores/bqml_arima.explore"
include: "model_name_suggestions.explore"
explore: ito_ham_stock_price_prediction {
label: "BQML ARIMA Plus: Itoham stock price ARIMA"
description: "Use this Explore to create BQML ARIMA Plus models to forecast stock price for itoham"
extends: [bqml_arima]
join: arima_forecast {
type:full_outer
relationship: one_to_one
sql_on: ${input_data.date} = ${arima_forecast.forecast_date} ;;
}
}input_data.view 中身
include: "//bqml-arima/**/input_data.view"
view: +input_data {
label: "[1] BQML: Input Data"
derived_table: {
sql:
SELECT
(stock_2296._date_ ) AS stock_2296__date__date,
stock_2296.close AS stock_2296_m_close,
nzd_jpy_kawase.close/(LEAD(nzd_jpy_kawase.close) OVER (ORDER BY stock_2296._date_ DESC))-1 AS kawase_prev_change,
stock_2296.close/(LEAD(stock_2296.close) OVER (ORDER BY stock_2296._date_ DESC))-1 AS ito_ham_prev_change
FROM `rie-playground.market_data.stock_2296` AS stock_2296
INNER JOIN `rie-playground.market_data.nzd_jpy_kawase` AS nzd_jpy_kawase ON stock_2296._date_ = nzd_jpy_kawase._date_
ORDER by 1 desc
;;
}
dimension: date {
#primary_key: yes
type: date
datatype: date
sql: ${TABLE}.stock_2296__date__date ;;
}
dimension: stock_2296_m_close {
type: number
sql: ${TABLE}.stock_2296_m_close ;;
}
dimension: kawase_prev_change {
type: number
sql: ${TABLE}.kawase_prev_change ;;
}
dimension: ito_ham_prev_change {
type: number
sql: ${TABLE}.ito_ham_prev_change ;;
}
dimension: total_visits {
hidden: yes
}
dimension: total_new_visits {
hidden: yes
}
dimension: total_pageviews {
hidden: yes
}
dimension: total_hits {
hidden: yes
}
dimension: total_bounces {
hidden: yes
}
dimension: total_time_on_site {
hidden: yes
}
dimension: total_transactions {
hidden: yes
}
dimension: total_transaction_revenue {
hidden: yes
}
}exploreは、元のblocksにあるものをextendsして、forcastとinput_data部分の条件を上書きしています。
Input_data.viewは元のblocksにあるものをrefinementsして、元のinput_dataにあった不必要なフィールドはhiddenしています。

ここで、トレーニングデータとして何を入れるか、結構考えました。むやみにデータを入れても、いい予測はできないので、データを一旦調べてから、予測に役に立ちそうなfeatureを見つけてあげる工程が発生します。いろいろ試行錯誤して、一旦、伊藤ハムの各日の終値と、前日からの終値の変化率、NZD/JPY為替の前日終値からの変化率を使うことにしました、伊藤ハムがニュージーランドあたりで輸入輸出を行っているため、為替の状況に業績が影響することと、為替の動向が株価の変化に先行しているように見えたのでこれでやってみます。なんとなくファンダメンタルとテクニカルがごっちゃになっていますが、お遊びなのでツッコミは受け付けません〜
このマーケットデータですが、日毎の4本値データであれば、investing.comからcsvダウンロードができます。APIはないので、今回みたいなone-offのプロジェクトだったらまぁ人力でいいかという感じです。
- model_name_suggestions.exploreのカスタマイズ
model_name_suggestions.explore 中身
include: "//bqml-arima/**/model_name_suggestions.explore"
explore: +model_name_suggestions {
sql_always_where: ${model_info.explore} ='ito_ham_stock_price_prediction';;
}sql_always_whereの右辺を先程作成したexplore名を指定します。
このblocksでは、以前使用されたモデルをフィルタから選ばせたり、フィルタの部分から新しいモデル名をインプットして、作成するといったことができます。この今までに作成されたモデルは、BQML_ARIMA_MODEL_INFOのテーブルに保存されており、suggetionもここから作成されます。
これで準備ができたので早速予測してみます!
Exploreのフィールドピッカー(左側のフィールド選ぶところのことです)の各ビューに番号が振られているので、素直にこの順番で操作していきます。
- モデル作成
a) まず、[1] input dataから、トレーニングに使用するフィールドを選んでクエリします 2011年からのマーケットデータを使っているので、行制限を5000行に変えました
b) 次に、[2] Name your modelから、今回は初めてモデル作成するので、モデルの名前を入力します - [3] Select Training Dataから、モデル作成に必要な、time fieldおよび、予測したい対象のフィールドを設定します。こちらも、フィルターの候補のところに、input_dataのviewで作成したフィールドのリストが出てくるので、選ぶだけでOKです。今回は、伊藤ハムの終値を予測したいので、終値を選びます。
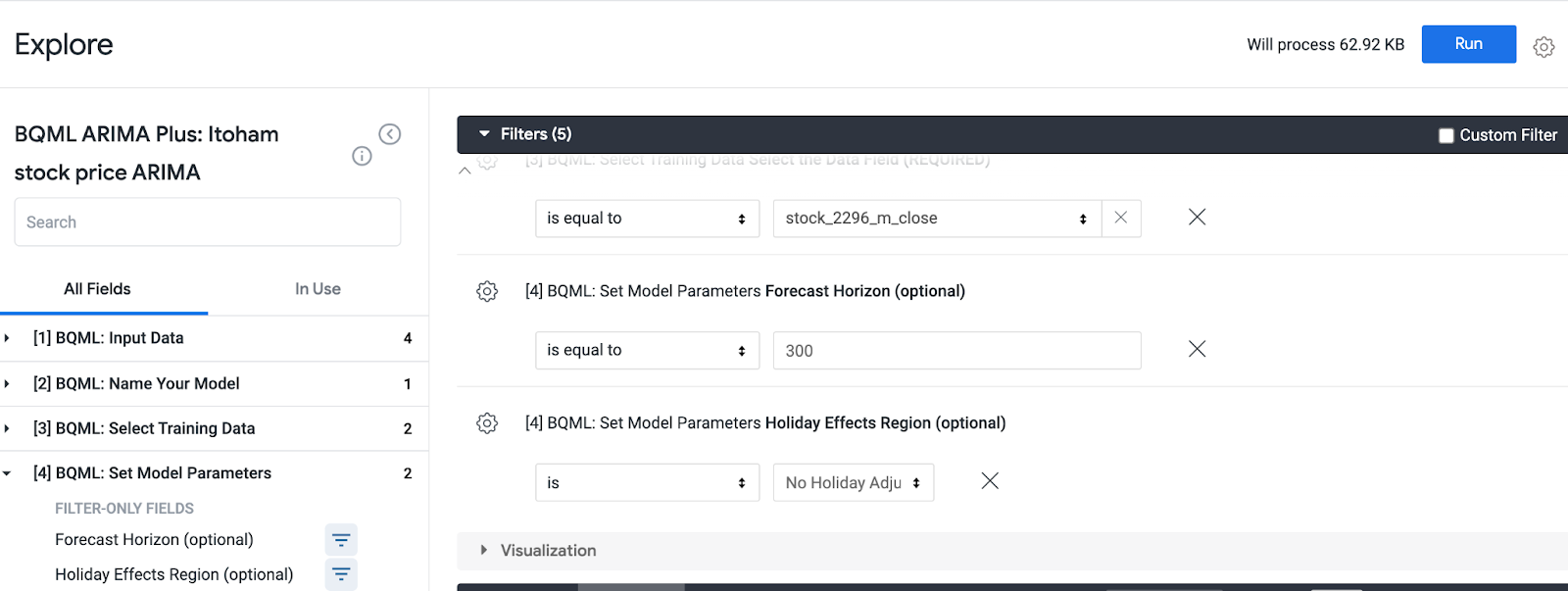
- [4] Set Model Parametersから、必須ではないですが、どれぐらい先を予測するのか、また休日効果を適用する場合のカレンダーを選ぶことができます。1000日も必要ないので、一旦300にして、休日効果はなしで設定します。
-
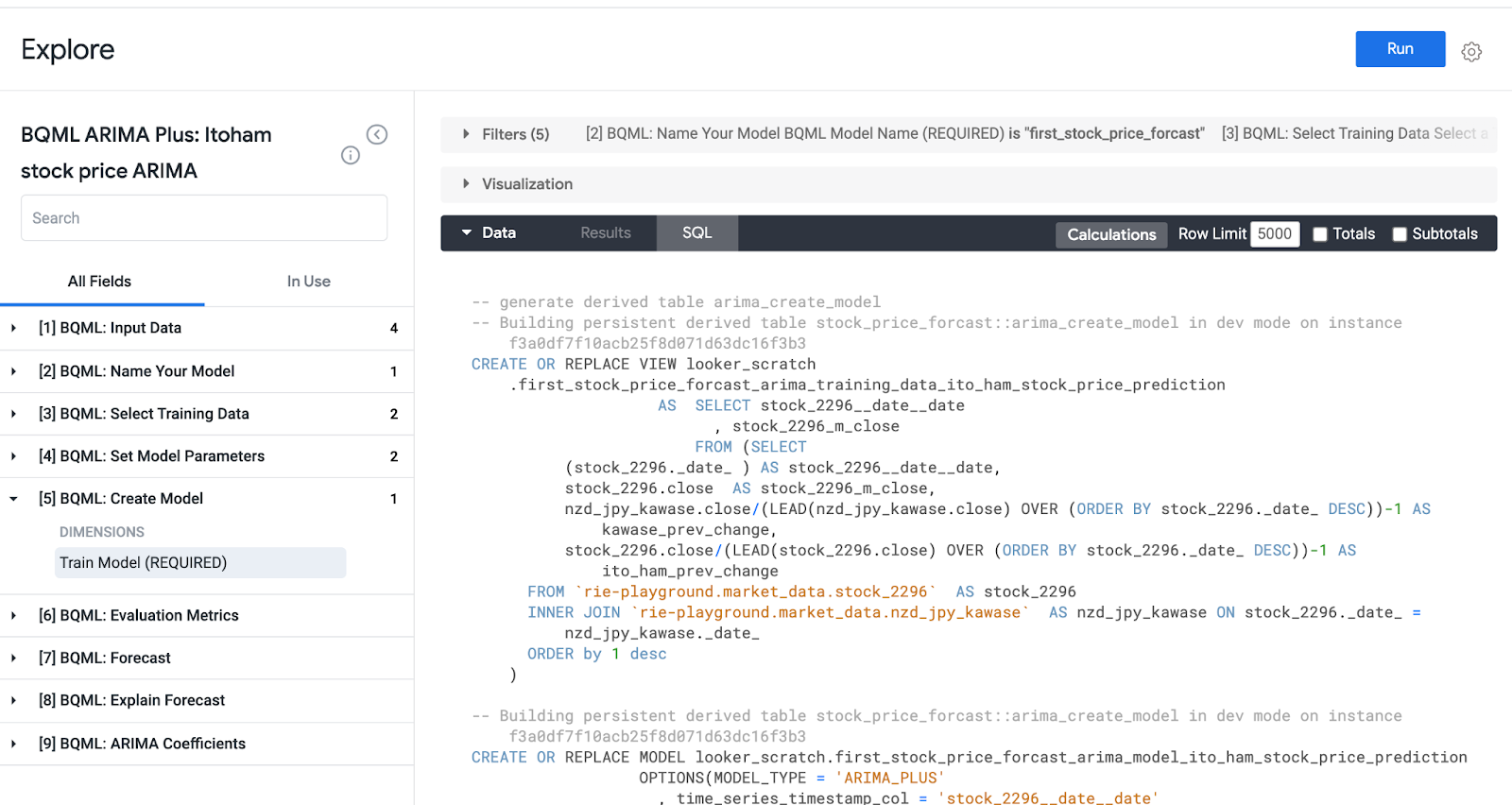
これで、モデル作成に必要な情報が用意できたので、[5] Create Model のTrain Modelのdimensionを選んで、最後に実行します。ここで初めて裏側で、BQMLのモデル作成、トレーニングのSQLが構築され、実行されます。(SQLタブ)
完了すると、先程追加したTrain Modelのdimensionに'Completed'の文字が出現するので、わかりやすいですね。28.6sかかっています。
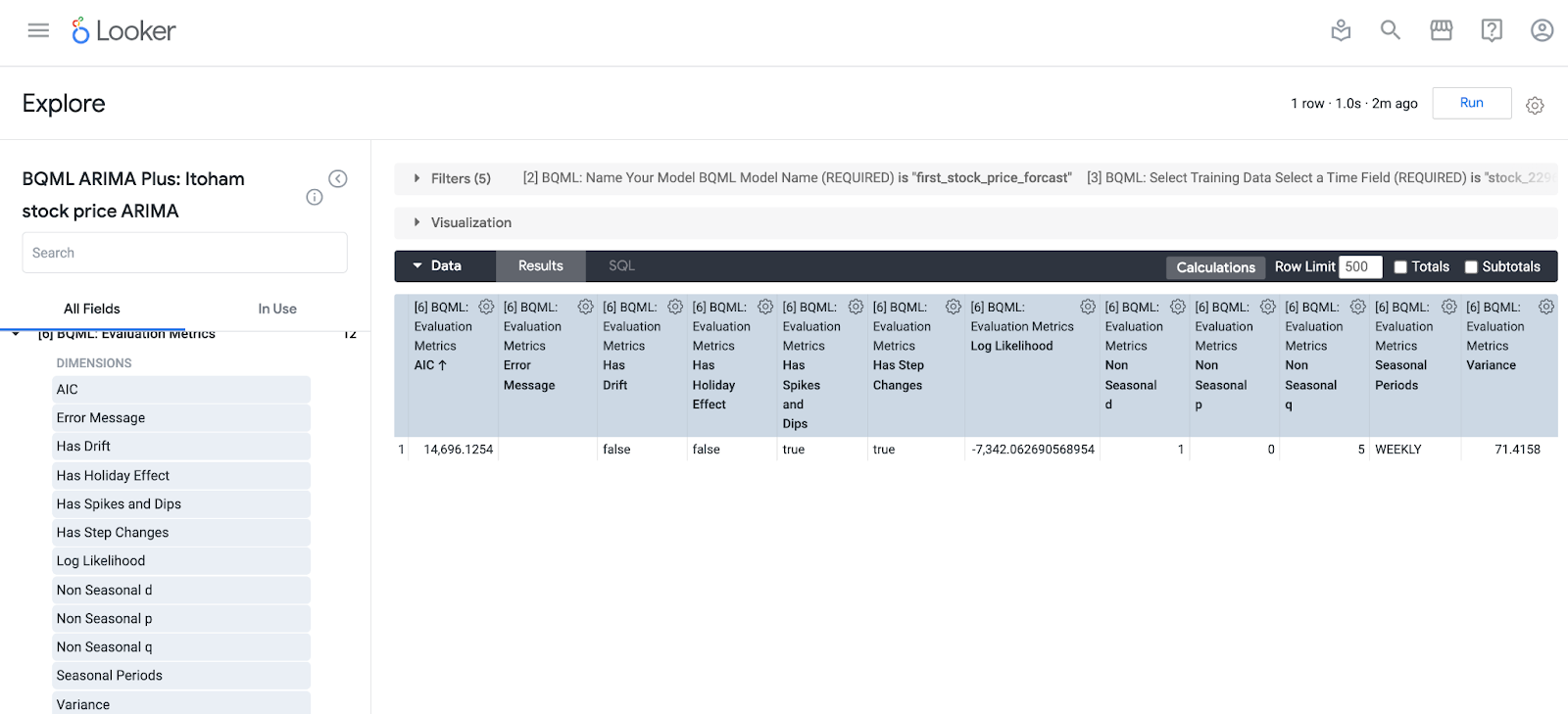
5. 作成したモデルの評価(1)
[6] Evaluation Metricsにて、各評価メトリクスを見ることができます
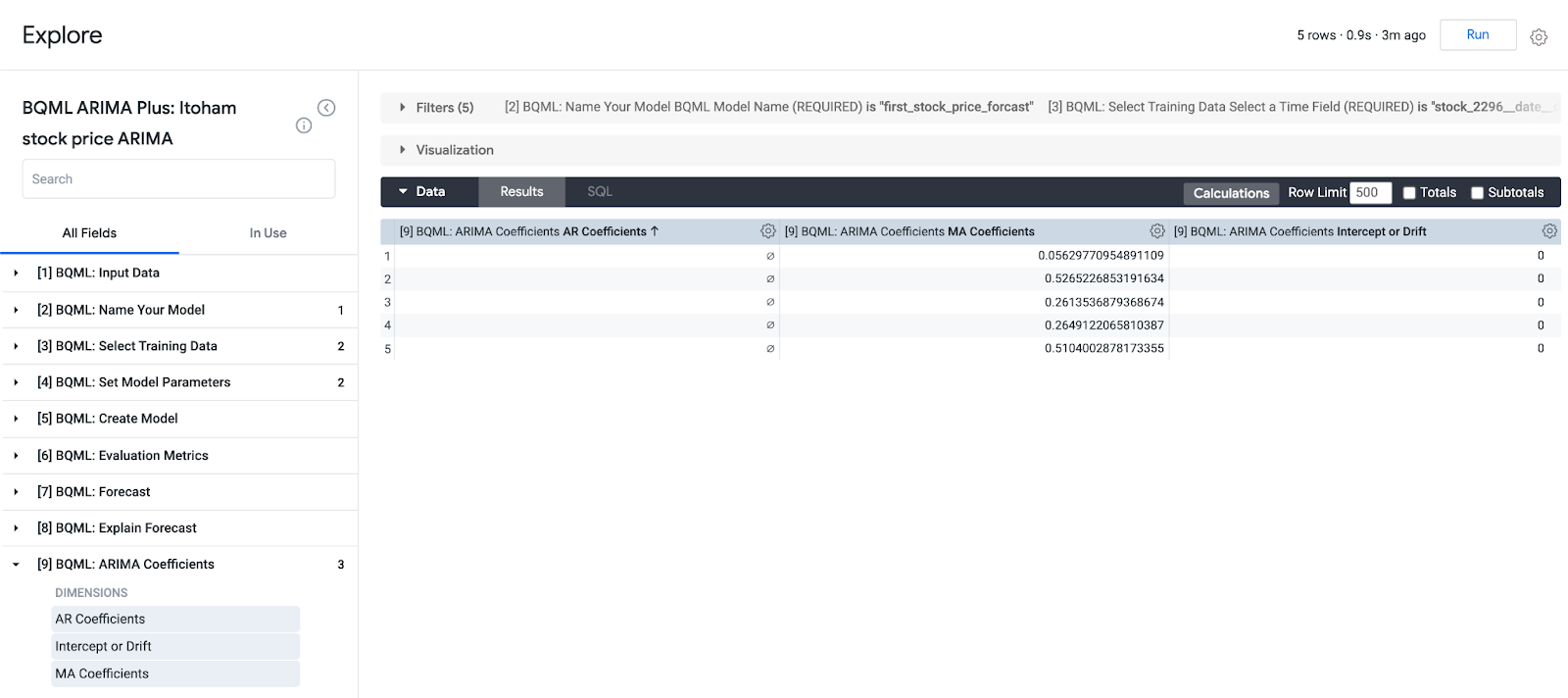
6. 作成したモデルの評価(2)
[9] ARIMA Coefficientsから、モデルの係数を確認します
7. そして、最後に予測した値を見てみましょう!
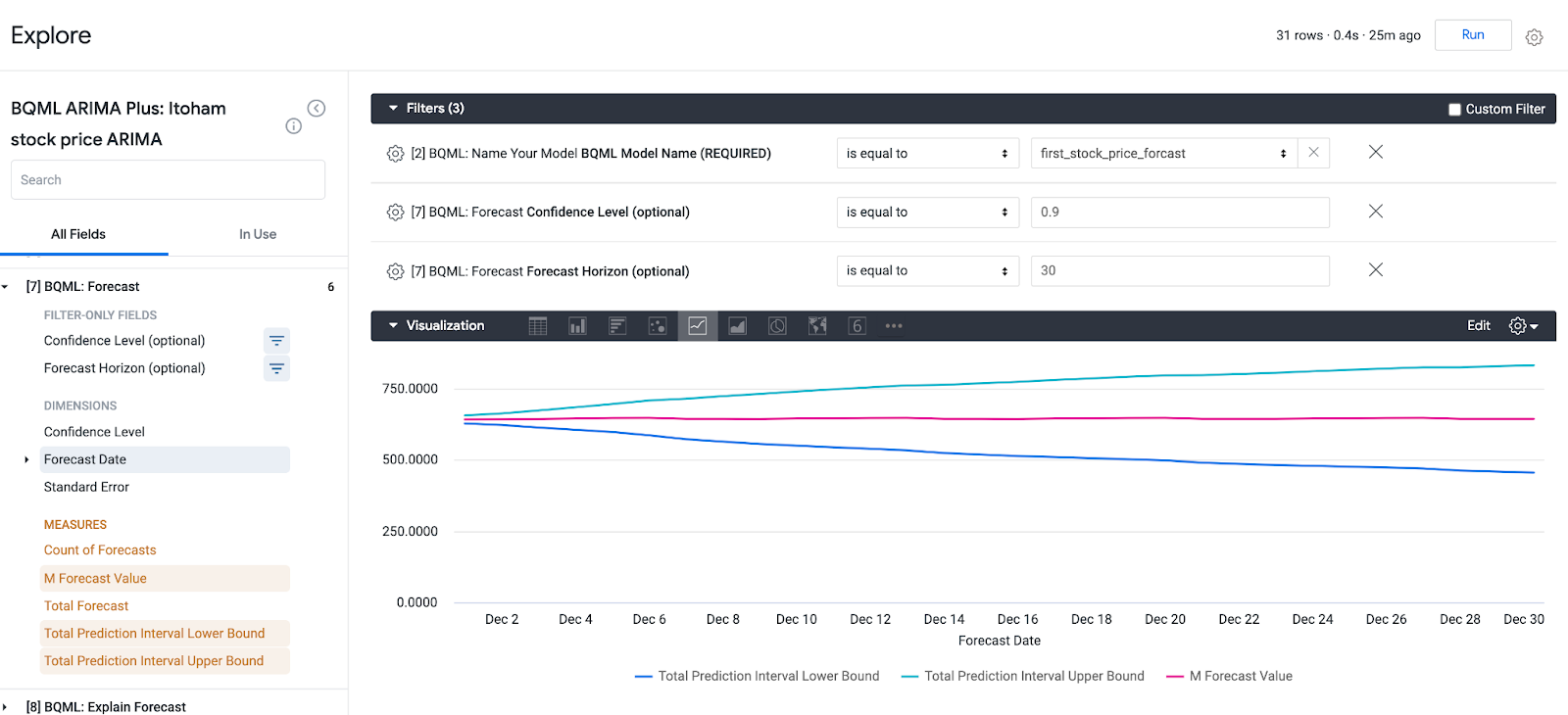
[7] Forecastから、Forecast dateと予測値のupper bound/lower bound、実際の予測値を出してみます。また今回は信頼度レベル90%、30日分の結果を見てみます。
こんな感じになりました。こんなにフラットになるかしらという感じですが、この記事が日の目を見る12月22日の株価は643.8だそうです。執筆時点(12/1)の終値は、633だったので、上がるだろうってことでとりあえず買ってみてもよさそうです。
この記事をアップロードする前日の21日の終値は649だったので、約5円ぐらいの差分でした。ちなみに、シンプルに伊藤ハムの終値だけを使って予測した場合は、21日の予測は637円だったのでちょっと精度が落ちます。



まとめ
なんだか個人のブログみたいな内容になってしまいましたが、
LookerでBQMLを扱うところがすごく簡単になりました!
っていうところと、
BQMLはunivariateだから、いろいろな要素が絡む株価の予測にはあまり向いてないんじゃと個人的に 思っています。機械学習路線で予測するのだとしたら、TensorFlowとか使った方が望みがありそうなので、そちらにチャレンジしてみたいと思います。
3
0
387
Topic Labels
- Labels:
-
blocks
0 REPLIES 0
Top Labels in this Space
-
access grant
6 -
actionhub
1 -
Actions
8 -
Admin
7 -
Analytics Block
25 -
API
25 -
Authentication
2 -
bestpractice
7 -
BigQuery
69 -
blocks
11 -
Bug
60 -
cache
7 -
case
12 -
Certification
2 -
chart
1 -
cohort
5 -
connection
14 -
connection database
4 -
content access
2 -
content-validator
5 -
count
5 -
custom dimension
5 -
custom field
11 -
custom measure
13 -
customdimension
8 -
Customizing LookML
114 -
Dashboards
144 -
Data
7 -
Data Sources
3 -
data tab
1 -
Database
13 -
datagroup
5 -
date-formatting
12 -
dates
16 -
derivedtable
51 -
develop
4 -
development
7 -
dialect
2 -
dimension
46 -
done
9 -
download
5 -
downloading
1 -
drilling
28 -
dynamic
17 -
embed
5 -
Errors
16 -
etl
2 -
explore
58 -
Explores
5 -
extends
17 -
Extensions
9 -
feature-requests
6 -
filter
220 -
formatting
13 -
git
19 -
googlesheets
2 -
graph
1 -
group by
7 -
Hiring
2 -
html
19 -
ide
1 -
imported project
8 -
Integrations
1 -
internal db
2 -
javascript
2 -
join
16 -
json
7 -
label
6 -
link
17 -
links
8 -
liquid
154 -
Looker Studio Pro
1 -
looker_sdk
1 -
LookerStudio
3 -
lookml
859 -
lookml dashboard
20 -
LookML Foundations
52 -
looks
33 -
manage projects
1 -
map
14 -
map_layer
6 -
Marketplace
2 -
measure
22 -
merge
7 -
model
7 -
modeling
26 -
multiple select
2 -
mysql
3 -
nativederivedtable
9 -
ndt
6 -
Optimizing Performance
28 -
parameter
70 -
pdt
35 -
performance
11 -
periodoverperiod
16 -
persistence
2 -
pivot
3 -
postgresql
2 -
Projects
7 -
python
2 -
Query
3 -
quickstart
5 -
ReactJS
1 -
redshift
10 -
release
18 -
rendering
3 -
Reporting
2 -
schedule
5 -
schedule delivery
1 -
sdk
5 -
singlevalue
1 -
snowflake
16 -
sql
219 -
system activity
3 -
table chart
1 -
tablecalcs
53 -
tests
7 -
time
8 -
time zone
4 -
totals
7 -
user access management
3 -
user-attributes
9 -
value_format
5 -
view
24 -
Views
5 -
visualizations
166 -
watch
1 -
webhook
1 -
日本語
3
- « Previous
- Next »